LLM Misconception: Why Word Prediction, Not Reasoning, Must Drive Your AI Strategy
Dec 1, 2025

We need to start by breaking a bad habit.
When we talk about Large Language Models (LLMs) like GPT-5.1 or Gemini 3, we tend to anthropomorphize them. We use words like "thinks," "knows," or "hallucinates." While convenient, these terms are dangerous for business leaders because they imply that the model is a digital employee with a reasoning brain.
It is not.
At its core, an LLM is a multi-purpose neural network designed to do exactly one thing: predict one word after the next [1].
Understanding this fundamental, mechanical distinction is the difference between building a robust, high-ROI application and building a novelty toy that fails immediately in production.
LLM Mechanism: Why Word-Prediction is NOT Reasoning
If you strip away the chat interface, an LLM is a massive statistical file. It predicts words by performing billions of matrix multiplication steps based on "parameter weights."
Think of it as "Autocorrect on Steroids."
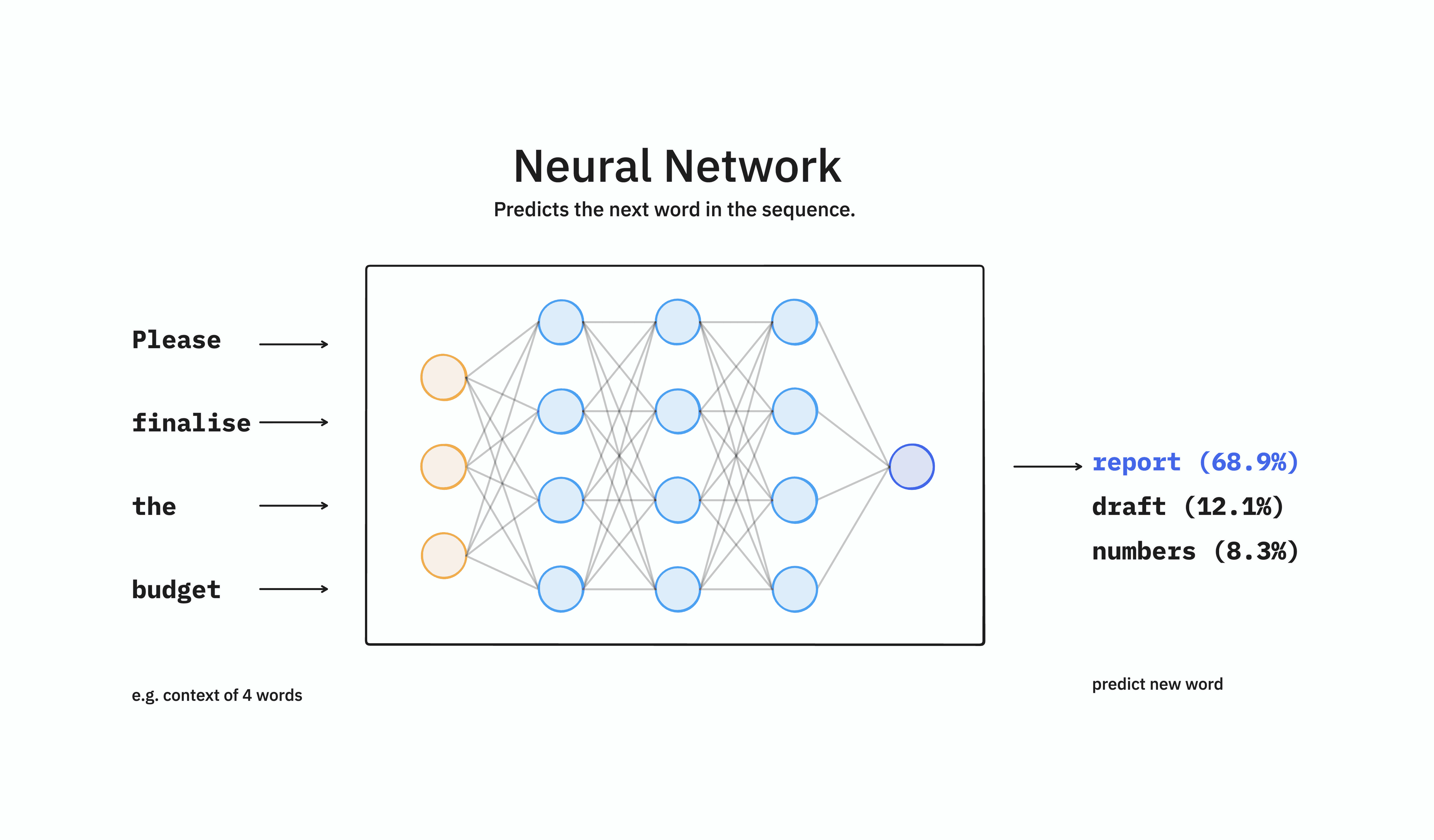
When you type on your phone, the software guesses the next word based on the previous three words. An LLM does the same, but instead of looking at three words, it looks at a "Context Window" that can contain thousands of pages of text. It calculates the probability of every possible next word (or "token") and selects one [2].
This helps explain the "hallucination" problem. The model does not "know" facts in the way a database does. It stores the statistical relationship between words. If you ask for a Q3 sales report that doesn't exist in its training data, it will not say "I don't know." It will predict the most statistically probable words that look like a sales report. It is prioritizing plausibility over truth.
Astronomical Cost of LLM Training: Why Retraining is NOT an Option
How do these models get so smart if they are just predicting words?
The answer lies in the scale of training. Open-source models are trained on massive amounts of text from every conceivable genre and topic. This process, called "Pre-training," is incredibly capital intensive.
The Resource Trap: Training a modern state-of-the-art model from scratch requires discarding trained weights and using only the architecture to train on a specialized dataset.
The Price Tag: OpenAI's GPT-4 reportedly cost more than $100 million, with estimates ranging from $63 million to $78 million in compute costs alone. Google's Gemini Ultra model is estimated to have cost $191 million in training compute [3].
Because of this astronomical cost, "retraining" a model from scratch is rarely the right business decision. Instead, we use these general-purpose models as a foundation.
Strategic Reality: From Probabilistic to Deterministic
For the business leader, the LLM is not a "Knower of Truth." It is a "Reasoning Engine."
It is excellent at formatting, summarizing, translating, and extracting data because those tasks rely on language patterns. However, it is fundamentally terrible at retrieving specific, real-time proprietary data because that data is not in its frozen weights [4].
This leads us to the central challenge of AI adoption: How do we force a probabilistic engine to be deterministic?
We cannot rely on simple "Prompt Engineering" alone. Conveying intention to an LLM through a system prompt is a brittle solution and often a "stopgap measure" that is unsustainable in the long term. Your business requires predictability, not continuous prompt tuning [5].
To deploy AI at scale, you must mandate an architecture that separates the model’s linguistic ability from your proprietary data.
The required strategic shift must be visualized this way: we must move beyond simple prompting and focus on two core customization strategies:
Strategy | Primary Business Goal | Example |
|---|---|---|
RAG (Retrieval-Augmented Generation) | Injecting up-to-date, proprietary Facts. | Pulling current stock prices, internal HR policies, or yesterday's sales figures. |
Fine-Tuning | Shaping the model's Behavior and Tone. | Making the model sound like a compliance officer or a marketing copywriter. |
The success of AI adoption in your business won't come from a magic prompt or a generalized model, it will come from treating the LLM not as an oracle, but as the powerful, probabilistic tool it is, and strategically connecting it to the deterministic data only your business owns.
Citations
Sebastian Raschka - Understanding and Coding the Self-Attention Mechanism of Large Language Models From Scratch (https://sebastianraschka.com/blog/2023/self-attention-from-scratch.html)
Claude - Context windows (https://platform.claude.com/docs/en/build-with-claude/context-windows)
Cudo Compute - What is the cost of training large language models? (https://www.cudocompute.com/blog/what-is-the-cost-of-training-large-language-models)
OpenAI - Why language models hallucinate (https://openai.com/index/why-language-models-hallucinate/)
Frontiers in - Survey and analysis of hallucinations in large language models: attribution to prompting strategies or model behavior (https://www.frontiersin.org/journals/artificial-intelligence/articles/10.3389/frai.2025.1622292/full)
Frequently Asked Questions (FAQ)
Q: What is the fundamental mechanism of a Large Language Model (LLM)?
A: At its core, an LLM is a multi-purpose neural network designed to do exactly one thing: predict the most statistically probable next word (or token) based on its training data.
Q: Why do LLMs "hallucinate"?
A: LLMs hallucinate because they prioritize plausibility over truth. Since they store the statistical relationship between words rather than facts, if asked for unknown information, they predict the words that look most like the answer, rather than saying "I don't know."
Q: As a business leader, when should I choose RAG over Fine-Tuning for my LLM application?
A: Choose RAG (Retrieval-Augmented Generation) when your primary need is injecting up-to-date, proprietary facts (e.g., live sales data). Choose Fine-Tuning when your primary need is shaping the model's behavior, tone, and formatting style.

Ready to transform your Business?
Bring Us Your Vision: Every great app starts with an idea. Whether it's a sketch on a napkin or a fully-fledged business plan, share your dream with us

Based in Dubai, UAE
©2025 Jeem Studio Technology